

Многоязычный сайт на битриксе из коробки – боль. Поэтому вы оказались на этой странице. Архитектурно разработчики БУС более-менее сделали поддержку языковых переменных в отдельных файлах, которые вызываются через GetMessage(). Это требует времени и усидчивости, но работает. Переводы инфоблоках создателями не предусмотрены.
Единственным решением было сделать полную физическую копию инфоблоков, привязать к сайтам (s1, s2 и т.д.) и в коде вызывать нужный перевод. Это сложно даже для контентных сайтов, а про интернет-магазины с интеграцией остатков и цен с 1С молчу – много времени разработчика, много скриптов, перегруженные контент-менеджеры. Так дело не пойдет.
Настоящая мультиязычность – это один инфоблок, одно дерево категорий и контент, который адаптируется под пользователя на лету. Да, движок для сайта Битрикс крайне мощный. Но разрабатывать единый двуязычный (трех-, четырех- и т.д.) сайт – значит дублировать инфоблоки, раздувать базу данных, усложнять поддержку разработчиками и контент-менеджерами. Базовое ядро D7 не умеет хранить версии одного элемента даже на двух языках из коробки.
За 16 лет проектирования сайтов на bitrix я устал бороться с ограничениями платформы. Клиенты постоянно спрашивали, как поменять язык в битриксе без мучительного дублирования контента. Поэтому написал собственный архитектурный модуль mrlexndr.translate, который решает задачи мультиязычность 1с элегантно.
Ниже расскажу о девяти сложностях, с которыми сталкивается мультиязычность, и покажу на примерах кода, как их закрыл.
Боль 1: лавинообразные нагрузки (Cache Stampede)
Как принято: фразы интерфейса хранят в файлах /lang/ и выводят через битрикс GetMessage(). Включают кеширование компонентов, чтобы сервер не упал от тысяч запросов. В мультиязычной среде параметр текущего языка LANGUAGE_ID добавляют в идентификатор кеша.
Если на сайте пять языков, размер кеша увеличивается в пять раз. Менеджер меняет одну запятую, тегированный кеш сбрасывается для всех языков одновременно. Сервер получает шквал запросов к базе на перегенерацию страниц (Cache Stampede).
Стандартный подход (вызывает нагрузку при инвалидации)
// Использование стандартного ядра
use Bitrix\Main\Localization\Loc;
Loc::loadMessages(__FILE__);
// Если кеш сбросится, Битрикс пойдет искать файлы на диске
echo Loc::getMessage('ORDER_BTN_TEXT');
Решение через модуль: PHP Array Generation и OPcache
Я отказался от механизма \Bitrix\Main\Data\Cache для статических словарей. Модуль атомарно генерирует физический файл vocab_ru.php (vocab_любойязык) в виде PHP-массива. Файл сохраняется в OPcache сервера. Доступ к переводу фразы происходит за время O(1) без единого запроса к базе данных или диску.
// Глобальный хелпер, работает напрямую из OPcache
// 'Оформить заказ' - текст по умолчанию, если фразы еще нет в базе
echo LANG_VAR('ORDER_BTN_TEXT', 'Оформить заказ');
Боль 2: костыли в шаблонах компонентов
Как принято: чтобы англоязычная версия сайта работала от единого дерева, программисты создают дополнительные свойства инфоблока: NAME_EN, PREVIEW_TEXT_EN. Затем идут в файлы result_modifier.php каждого компонента и пишут костыли. Многосайтовость bitrix здесь мстит за попытку от нее уйти.
Стандартный подход
// result_modifier.php стандартного news.list
foreach ($arResult['ITEMS'] as &$item) {
if (LANGUAGE_ID === 'en') {
if (!empty($item['PROPERTIES']['NAME_EN']['VALUE']) {
$item['NAME'] = $item['PROPERTIES']['NAME_EN']['VALUE'];
}
if (!empty($item['PROPERTIES']['PREVIEW_TEXT_EN']['VALUE'])) {
$item['PREVIEW_TEXT'] = $item['PROPERTIES']['PREVIEW_TEXT_EN']['VALUE'];
}
} elseif (LANGUAGE_ID === 'es') {
if (!empty($item['PROPERTIES']['NAME_ES']['VALUE']) {
$item['NAME'] = $item['PROPERTIES']['NAME_ES']['VALUE'];
}
if (!empty($item['PROPERTIES']['PREVIEW_TEXT_ES']['VALUE'])) {
$item['PREVIEW_TEXT'] = $item['PROPERTIES']['PREVIEW_TEXT_ES']['VALUE'];
}
}
}
unset($item);
Решение через модуль: D7 ORM QueryHelper
Правильно делать локализацию не во View (шаблонах), а на уровне Model (запросов). Я вынес логику подмены полей в D7. Если нужен битрикс на английском, класс QueryHelper сам модифицирует массив SELECT до запроса в базу.
foreach ($arResult['ITEMS'] as &$item) {
IblockHelper::substituteStandardFields($item);
}
Боль 3: ад контент-менеджера и перевод JSON
Как принято: при поддержке четырех языков карточка товара дублируется четыре раз. Заполнять вручную — каторга. Если лендинг собран в визуальном конструкторе (Sprint Editor), где данные лежат в JSON, перевод превращается в хирургическую операцию руками контент-менеджера.
Стандартный подход (мануальный парсинг JSON)
// Чтобы перевести Sprint Editor, программисты пишут такие скрипты:
$data = json_decode($element['PROPERTY_CONTENT_VALUE'], true);
foreach ($data['blocks'] as &$block) {
if ($block['name'] === 'text') {
// Переводим текст вручную или отправляем в API
$block['value'] = my_custom_translate_func($block['value'], LANGUAGE_ID); //какая-то кастомная функция
}
}
Решение через модуль: пакетный ИИ-переводчик
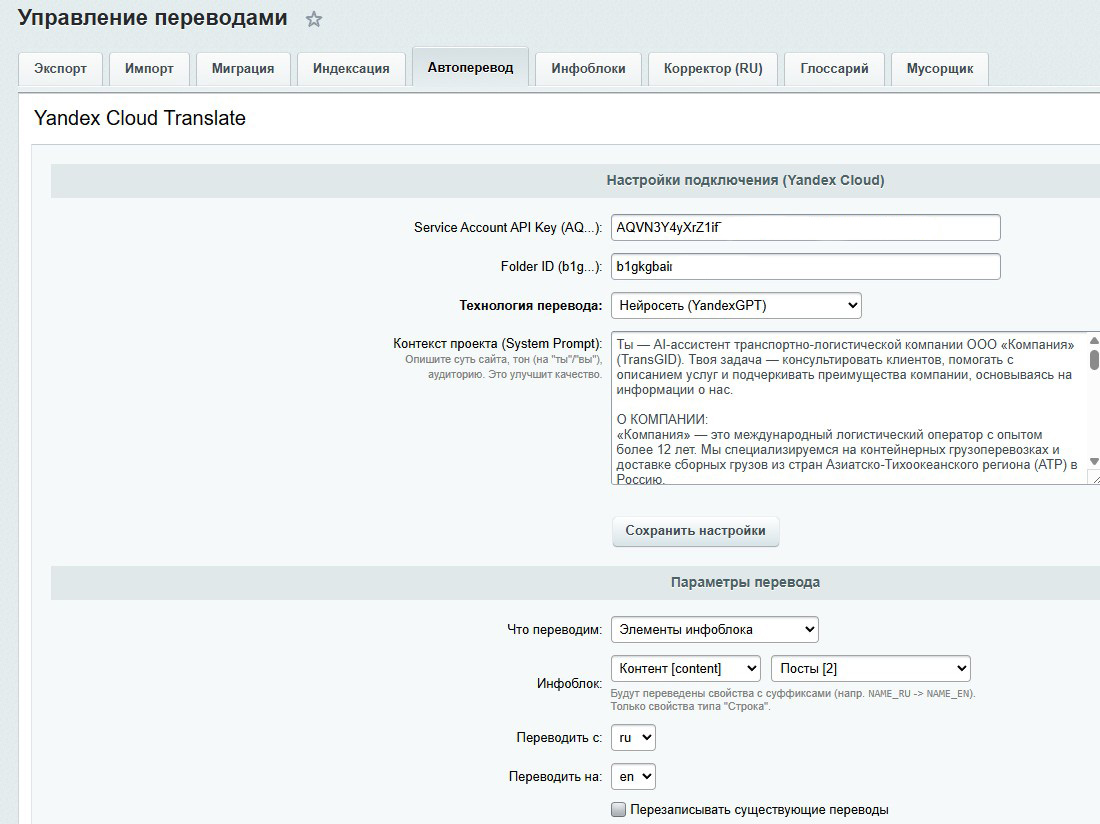
Я встроил в админку асинхронный переводчик на базе YandexGPT. Менеджер заполняет контент только на русском, нажимает кнопку, и скрипт в фоне (AJAX-шагами) переводит свойства. Для Sprint Editor написал сервис JsonTranslator, который обходит JSON-дерево, вытягивает тексты, переводит пачкой через ИИ, раскладывает обратно и сохраняет верстку.
// В админке это делается по кнопке, но под капотом работает так:
$translatedJson = \mrLexndr\Translate\Lang::translateSprintJson(
$jsonContent,
'ru',
'en',
$apiKey,
$folderId
);
Боль 4: игнорирование локальной типографики
Как принято: текст прогоняют через машинный перевод. Получаете висячие предлоги в русском, отсутствие нужных пробелов перед пунктуацией во французском и сломанные отступы в китайском. Мультирегиональность битрикс требует культурной адаптации типографики.
Стандартный подход (хрупкие регулярки)
// Попытки расставить неразрывные пробелы вручную
$text = preg_replace('/ (\w{1,2}) /u', ' $1 ', $text);
$text = str_replace(' - ', ' — ', $text);
Решение через модуль: UniversalSpacer
Модуль прогоняет тексты через сервис UniversalSpacer. Он знает специфику языков: привязывает короткие предлоги в кириллице, ставит неразрывный пробел перед знаками пунктуации во французском (?, !, :) и корректно удаляет мусорные пробелы между CJK-иероглифами.
// В шаблоне или при сохранении элемента:
$cleanText = \mrLexndr\Translate\Lang::typo($text, LANGUAGE_ID);
// Автоматически маскирует HTML и применяет правила типографики языка
Боль 5: поиск нужной фразы в коде
Как принято: редактор находит на сайте опечатку, гуглит «битрикс мультисайтовость как изменить текст» или «битрикс как настроить перевод кнопок». Программист качает проект и ищет ключ глобальным поиском по файлам.
Стандартный подход
# Разработчик ищет фразу через консоль сервера
grep -r "ORDER_BTN_TEXT" /local/components/
Решение через модуль: Public Editor и CodeScanner
Я вывел управление фразами в публичную часть сайта в режиме Эрмитажа. Редактор наводит курсор на текст (вызванный через LANG_VAR) и кликает — откроется карточка редактирования. А если программист ищет шаблоны bitrix, в которых используется этот ключ, встроенный CodeScanner сам просканирует директории и выведет список файлов в админке.
// При вызове функции в режиме правки:
echo LANG_VAR('ORDER_BTN_TEXT', 'Оформить');
// Она автоматически сгенерирует HTML-обертку для Эрмитажа:
// // onclick="window.open('/bitrix/admin/...', '_blank');">Оформить
Боль 6: миграция языковых файлов и импорт переводов
Как принято: старый проект переводят на новую архитектуру. Встает задача перенести тысячи фраз из папок lang/ru/ и lang/en/. Разработчики пишут одноразовые скрипты-костыли. Когда дело доходит до работы с профессиональным бюро переводов, программисты выгружают данные в Excel прямыми SQL-запросами.
Стандартный подход (болезненный ручной перенос)
// Программист вынужден писать парсеры для каждого компонента
include '/local/components/my/comp/lang/ru/template.php';
foreach($MESS as $code => $val) {
// Попытки вставить данные в базу...
}
Решение через модуль: встроенная миграция и экспорт/импорт
Специальная вкладка «Миграция» в админке. Скрипт рекурсивно обходит директорию /local/, находит файлы локализаций, извлекает переменные $MESS и раскладывает в Highload-блок с переводами из параллельных языковых папок.
Для обмена с бюро переводов реализовал нативный CSV экспорт и импорт. Выгрузили базу в один клик, отдали переводчикам, загрузили обратно — проект локализован.
// Модуль сам генерирует корректный CSV со всеми языковыми полями:
fputcsv($out, ['UF_CODE', 'UF_LANG_RU', 'UF_LANG_EN'], ';');
// И так же легко парсит загруженный файл, создавая или обновляя фразы
Боль 7: искажение брендовой терминологии (глоссарий)
Как принято: машинный перевод Yandex или Google по-разному переводит одни и те же термины. На одной странице кнопка называется «Cart», на другой — «Basket». Нейросеть может перевести узкие термины сложного B2B-продукта так, что клиенты не поймут. Программистам приходится писать регулярные выражения для автозамен после перевода.
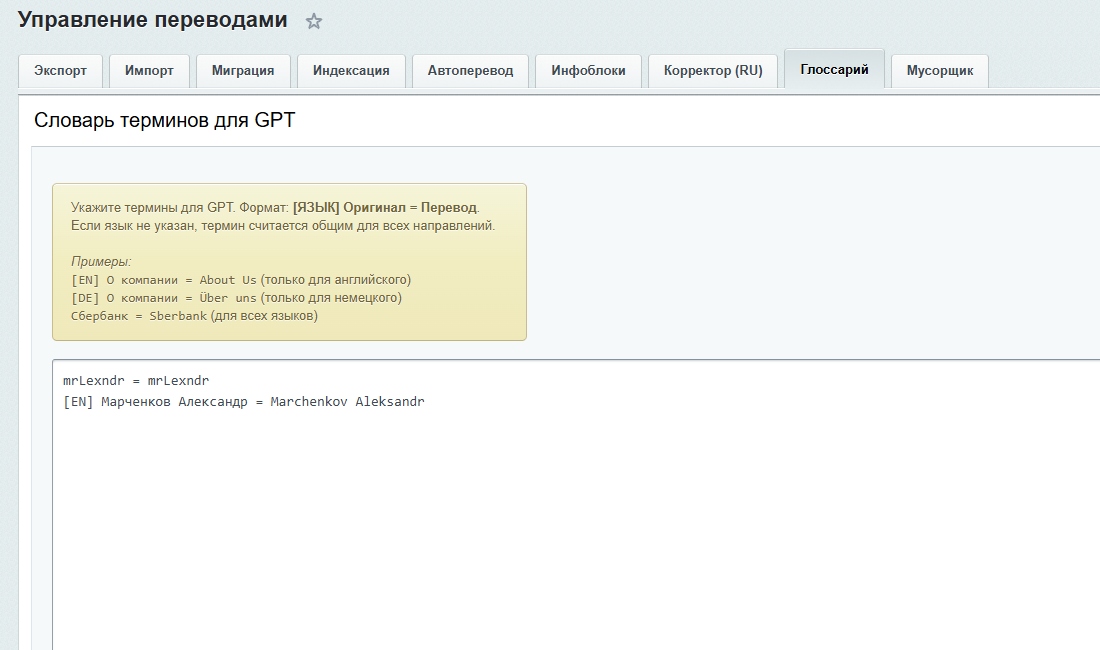
Решение через модуль: системный глоссарий для GPT
Текстовое поле «Глоссарий» в настройках модуля со списком правил в формате [EN] О компании = About Us. Драйвер YandexGptDriver берет эти правила и инжектит в системный промпт нейросети перед каждым запросом.
// Драйвер под капотом собирает промпт для YandexGPT:
$systemText .= "ОБЯЗАТЕЛЬНЫЙ ГЛОССАРИЙ (Термины использовать строго):\n";
$systemText .= $this->getGlossaryForLang('en') . "\n";
// В итоге нейросеть понимает контекст и никогда не ошибется в названии бренда
Боль 8: накопление мертвого кода (мусорщик)
Как принято: за годы жизни проекта старые шаблоны удаляются, а фразы в словаре остаются. Разработчики боятся удалять старые ключи, потому что никто не знает: «А вдруг ORDER_BTN_OLD_V2 еще используется?». В результате база пухнет от мусора.
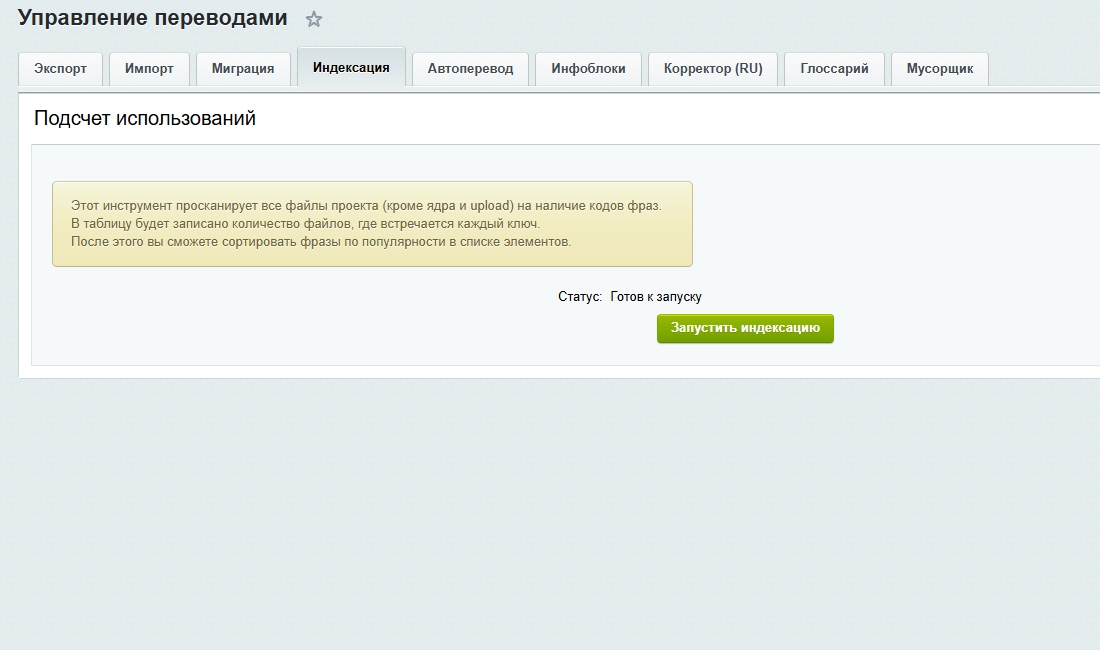
Решение через модуль: тотальная индексация и мусорщик
Инструмент пошаговой индексации. Модуль ищет ключи в PHP-файлах проекта и записывает в поле UF_USAGE_COUNT количество использований фразы в коде.
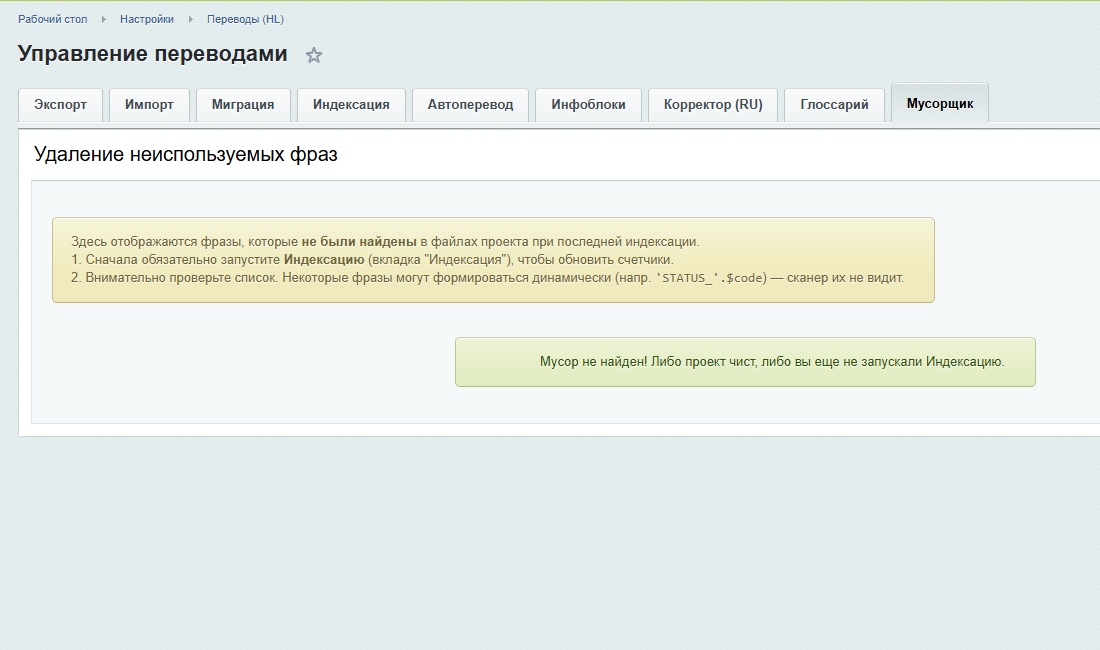
Фразы со счетчиком 0 автоматически попадают во вкладку «Мусорщик». Список мертвого кода можно безопасно очистить одной кнопкой.
// Мусорщик делает элементарный запрос к HL-блоку
$rsGarbage = $class::getList([
'filter' => [
'LOGIC' => 'OR',
['=UF_USAGE_COUNT' => 0],
['=UF_USAGE_COUNT' => false]
]
]);
// И показывает вам все, что давно пора удалить
Боль 9: неграмотный контент на базовом языке (корректор)
Как принято: переводить текст, в котором изначально куча орфографических ошибок. Контент-менеджеры часто лепят прямые кавычки вместо правильных «елочек», используют дефисы вместо тире и допускают опечатки. Обучать типографике — бесполезно.
Решение через модуль: AI-Корректор для русского языка
Модуль прогоняет русский текст через YandexGptCorrector перед переводом на другие языки. Драйвер работает с жестким системным промптом литературного редактора: исправляет орфографию, ставит длинные тире и «елочки», но сохраняет авторский стиль и не ломает верстку внутри HTML-тегов.
// Системная инструкция для GPT-корректора:
$systemText = "Ты — литературный корректор. Исправь ошибки и опечатки.\n";
$systemText .= "Заменяй прямые кавычки на елочки «...».\n";
$systemText .= "Не удаляй и не ломай HTML теги (,
, )...";
// На выходе получаем кристально чистый текст
Резюме
Сделать мультиязычный Enterprise-проект на едином инфоблоке — сложная задача. Нельзя установить плагин и надеяться, что заработает. Проект должен выдерживать нагрузки и быть удобен в поддержке. Выносим статику в OPcache, динамику перехватываем на уровне ORM, рутинный перевод отдаем нейросетям, а очистку словарей — автоматическим сканерам-мусорщикам. Только так выходим на международный рынок без накопления технического долга.
Комментарии (0)